干货分享 | SNP研究中,你一定遇到过这些问题,附解答!
来宝网 2023/8/23点击687次
干货分享 | SNP研究中,你一定遇到过这些问题,附解答!
SNP作为第三代分子标记,其应用非常广泛,在农业领域中,可以进行性状基因的精细定位、分子辅助育种、种子资源鉴定等;在医学领域中,可用于疾病的分子遗传机制研究、疾病基因定位、药物敏感或疾病易感性位点筛选等,生命科学研究的方方面面,都与之相关。
SNP的研究主要分为SNP的发现及SNP的基因分型。SNP的发现是应用的基础,而SNP的基因分型是应用的技术手段。新SNP通常是基于测序技术,利用已有数据库,对多个样本进行重测序发现的,但需要进行其他方法的验证;而已知SNP的基因分型可以通过芯片技术来筛选与表型相关的SNP,从中优选出多态性高,均匀分布的少量SNP,这些少量的SNP可以在大量样本中进行检测,根据样本情况、SNP数量、试验设计等选择合适的方法学。前段时间,小编和大家一起了解了SNP分型检测的几种常用方法、原理以及在不同领域的应用情况等,近期小编也收集到部分小伙伴关于SNP的问题,整理如下,方便大家进一步对一些细节性问题进行了解哦。
想了解SNP就得先了解什么是DNA的多态性。人与人之间绝大部分的DNA序列是一样的,DNA的多态性是指正常人群中,DNA分子或基因的某些位点可以发生改变,使DNA的一级结构各不相同,但并不影响基因的表达,形成多态;DNA的多态性可以看作是在分子水平上的个体区别的遗传标志。DNA多态性主要表现为反应限制性酶切位点变化的限制性片段长度多态性(RFLP)、反应重复单位拷贝数差异的串联重复序列多态性,以及反应点突变的单核苷酸多态性(SNP)等。
为什么说SNP是二等位基因系统,而不像RFLP和SSR是多等位基因系统?单核苷酸多态性(Single Nucleotide Polymorphisms,SNP)主要是指在基因组水平上由单个核苷酸的变异所引起的DNA序列多态性,即在群体中,基因组内特定核苷酸位置上存在两种不同的核苷酸,并且其出现的频率大于1%。SNP所表现的多态性只涉及到单个碱基的变异,这种变异可由单个碱基的转换(transition嘧啶和嘧啶之间或者嘌呤和嘌呤之间的交换)或颠换(transversion嘧啶和嘌呤之间的交换)所引起,也可由碱基的插入或缺失所致。SNP 在CG 序列上出现较为频繁,由于CG 中C 即胞嘧啶常被甲基化,自发脱氨后即变为胸腺嘧啶T,因此大多数情况下,都是发生的C→T的转换,而变成A和G的概率很小,所以一般认为SNP是二等位的,或者是二态性,即一个碱基只会突变为另一种碱基,而不会同时突变为另外多种碱基。由于SNP的二态性,非此即彼,在基因组筛选中SNPs只需要+/-的分析,而不用分析片段的长度,也让其应用更为广泛。
SNP是单碱基多态性,是一个群体概念,这个差异占群体的1%以上。若germline mutation频率<1%,则认为是一个点突变。SNP是各种生物都有的,通过同源基因比对获得的,一般不会发生变化,而点突变只对单一基因而言,所以从数量上SNP比点突变多得多。如果突变发生在生殖细胞,则可以遗传,但是只要这个突变群没有达到总群体的1%,它就只有一个突变株/系,达到了1%就是多态性了。
SNV,即单核苷酸位点变异(single nucleotide variants),SNP,即单核苷酸多态性(single nucleotide polymorphism),这两个概念都是指单核苷酸的改变,只不过SNP一般是二态的,而SNV没有这样的限制。另外,如果只是在病人体内检测到单个核苷酸的变异,而其在人群中出现的频率未知,则可看作SNV。
分子标记(Molecular Markers)是以个体间遗传物质即核苷酸序列变异为基础的遗传标记,是DNA水平遗传多态性的直接反映。根据分子标记检测的原理、技术手段以及通量效率,一般将分子标记分为三大类,分别是基于分子杂交技术的第一代分子标记、基于PCR技术的第二代分子标记以及基于测序技术的第三代分子标记。不同的分子标记技术如图1 所示。
最典型的代表类型如限制性片段长度多态性(RFLP),是以Southern杂交为核心设计。限制性片段长度多态性是指同种生物不同个体间DNA 序列产生差异,形成可被限制性内切酶识别的序列进而可被消化,被消化后的产物由于长度不同可通过电泳进行分型,RFLP操作简单、成本低廉,从而使RFLP被选为人类基因组计划的第一代遗传标记,用于基因图谱绘制、DNA指纹分析、疾病易感性分析、基因诊断、亲权鉴定等。包括随机扩增多态性DNA(random amplified polymorphic DNAs,RAPD),扩增片段长度多态性(Amplified Fragment Length Polymorphism,AFLP)、简单序列重复标记(SSR)等,也有学者仅将微卫星作为第二代分子标记代表,即短串联重复序列(STR)或简单重复序列(SSR),一般由2-6个核苷酸组成,是广泛分布在真核生物基因组中的简单重复序列。它具有多态性高、稳定可靠等特点,因此是一种十分理想的分子标记,在遗传图谱构建、数量性状位点(QTL)定位、标记辅助选择、遗传检测等领域都有着重要的应用价值。随着DNA测序技术的发展,以单核苷酸多态性(SNP)为代表的第三代分子标记迅速发展成为主流,SNP在所有生物的基因组中含量丰富,突变率较低,且获取的成本低,因此被广泛用于遗传多样性、系统发育分析和遗传和疾病相关基因的研究中。第1-3代分子标记中几种代表性的标记类型的特点如表1所示。
表1.第1-3代标记中几种代表性的DNA分子标记的特点

具有高的多态性,较高的多态水平和样本量,有利于在试验中检测出个体间的差异,差异性越大,越能体现出优势基因和优势基因型;
共显性遗传,即利用分子标记可鉴别二倍体中杂合和纯合基因型;
除特殊位点的标记外,要求分子标记均匀分布于整个基因组;
容易获得且可快速分析,检测手段便于实现自动化;
开发成本和使用成本尽量低廉;
在实验室内和实验室间重复性好(便于数据交换)。
SNP在基因组内的形式有哪些,都会对生物表型有影响吗?在基因组DNA中,任何碱基均有可能发生变异,因此SNP既有可能在基因序列内,也有可能在基因以外的非编码序列上。总的来说,有三类:位于基因周边的SNPs(pSNPs),位于基因间的SNPs(iSNPs),以及位于编码区内的SNP(codingSNP,cSNP)。
位于编码区内的SNP(cSNP)比较少,但由于它发生在编码区内,在遗传性疾病研究中具有重要意义,因此cSNP的研究更受关注。从对生物的遗传性状的影响上来看,cSNP又可分为2种:一种是同义cSNP(synonymous cSNP),即SNP所致的编码序列的改变并不影响其所翻译的蛋白质的氨基酸序列,突变碱基与未突变碱基的含义相同;另一种是非同义cSNP(non-synonymous cSNP),指碱基序列的改变可使以其为蓝本翻译的蛋白质序列发生改变,从而影响了蛋白质的功能。这种改变常是导致生物性状改变的直接原因。cSNP中约有一半为非同义cSNP。
位于非编码区域的SNP又可细分为两类,内含子中SNP对个基因功能的影响相对较小,主要依靠影响剪切位点活性来影响翻译,从而基因功能。而基因调控区域包含启动子区域、增强子区域等等,这些区域含有很多基因表达调控元件,这些位点的SNP发生变化,就会导致与调控因子的结合能力发生改变,从而影响正常的基因表达。
由美国国立生物技术信息中心(national center for biotechnology information,NCBI)建立、dbSNP 数据库制定的 SNP 命名体系,rs 体系的 SNP 代表已获得官方认可和推荐的参考 SNP(reference SNP),ss 体系的 SNP 代表用户新递交但尚未得到认可的 SNP(submitted SNP)。对于新发现的SNP位点,需要判断这些SNP位点是否已知。如果该SNP位点是前人报道,需要查找rs号和引用参考文献,如果为新发现的位点则需要将该位点递交到NCBI上,获得ss号。
SNPedia是一个SNP百科全书类网站,它引用已经发布的文章或者数据库信息,对SNP位点进行描述,共享着人类基因组变异的信息。我们可以搜索某个SNP位点来寻找与之相关的信息,也可以根据相关疾病和症状来寻找相关的SNP(图2)。网址:https://www.snpedia.com/index.php/SNPedia。

图2.SNPedia首页
- 如果是单基因遗传,特别是罕见遗传的疾病,可以通过外显子测序对一个家系的几个个体进行测序,筛选低频突变,随后找到能改变蛋白功能的突变,最后做共分离分析。
- 如果是多基因病或者质量性状定位,那么2个方法,一是全基因组关联分析GWAS,用散发型个体,进行关联分析,不过这种方法要的样本量比较大,一般都要好几百至好几千个样本。二是基因家系的连锁分析,这个主要是定位,然后在后续做一些东西,一般用芯片或者全基因组重测序或者简化基因组测序。
- 通过参考资料锁定研究相关的基因,通过数据库查到基因内部的 SNP 位点。
- 查找相关的参考文献,找到研究相关的 SNP 位点。
进行SNP位点验证,采用对照组和实验组的大量样本,验证目标SNP位点SNaPshot 法:基于多重PCR和ABI 3730xl 测序平台的 SNP 分型检测;
直接测序法:基于一代测序平台的SNP分型检测;
质谱法:基于Sequenom平台的SNP分型检测;
Taqman探针法:基于荧光定量PCR仪平台的SNP分型检测,等等。
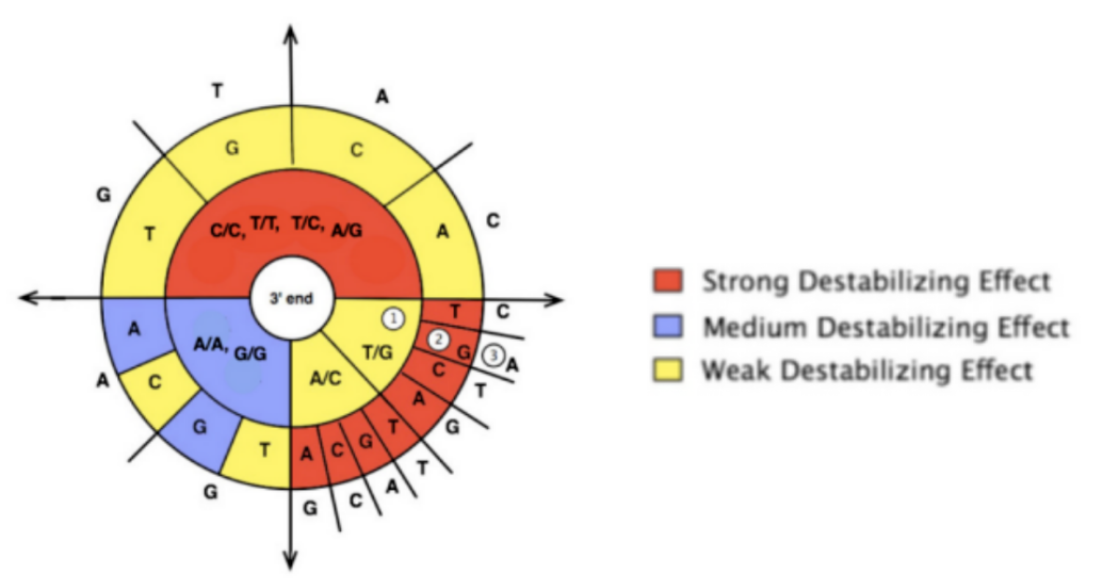
根据已有的对照组和实验组的SNP分型结果与实验目的进行关联分析,如与疾病的关联分析、遗传连锁分析、品种鉴定等ARMS PCR是基于Taq DNA聚合酶无法修复引物3’末端的单个碱基错配,从而使得扩增受阻的检测方法。该方法理论上单个碱基的错配即可阻碍PCR的扩增,但在实际检测时,单个碱基的错配依然可以延伸扩增,只是效率较低。为了提高其特异性,有时需在3’末端倒数第2位或第3位碱基处引入一个错配碱基,该错配碱基与3’末端的错配碱基共同作用,以降低非靶标序列的扩增效率。而如何设计错配碱基可参考如下标准(图3):1)当3’末端是“强”错配时(A/G或G/T)时,可以在引物中引入一个“弱”错配(C/A或C/T);2)当末端是“弱”错配时,则需要在引物中引入一个“强”错配;3)当末端是“中”错配时(A/A,C/C,G/G,T/T)时,可以在引物中再引入一个“中”错配。一般在3’末端倒数第三个碱基引入突变,可显著提高特异性。
虽然有以上强弱错配进行搭配的参考原则,但在实际产品开发过程中,小编还是建议把所有碱基错配类型全部尝试一遍,如引入错配位置模板为C碱基,则可考虑设计A/C、T/C、C/C三种错配进行筛选。此外理论上,3′端倒数第2或第3位错配筛选到合适引物的概率最高,但假如这两个位置效果都不理想,可尝试3′端倒数第4、5位,甚至是倒数第7位。如果从3′端倒数第2位至倒数第7位全部筛选,总共要筛选18条引物,引物的条数是比较多的,但是确实位置不同可能效果也不同,具体什么位置效果最好无法完全保证,只能靠验证结果来决定啦。
翌圣生物作为上游原料企业,在分子酶领域深耕多年,目前已开发了ARMS-PCR法及TaqMan探针法的SNP分型检测通用原料,已被下游厂家应用于肿瘤伴随诊断、药物基因组学、遗传病检测、疾病易感性研究等多个领域。
推荐仪器